Problem Setup
Let \(\mathcal{G}=(\mathcal{V},\mathcal{E})\) be a text-attributed graph with heterogeneous node/edge types, such as an academic network with papers, authors, and venues.
Each node \(v \in \mathcal{V}\) is associated with a set of textual fields (e.g., title, name, abstract) and typed relations to other nodes.
Given a question \(x\) and the graph environment \(\mathcal{G}\), the model needs to produce a natural-language answer \(y\) by interacting with \(\mathcal{G}\) through a set of executable graph functions.
We model the process of answering a question as an episodic Markov decision process (MDP).
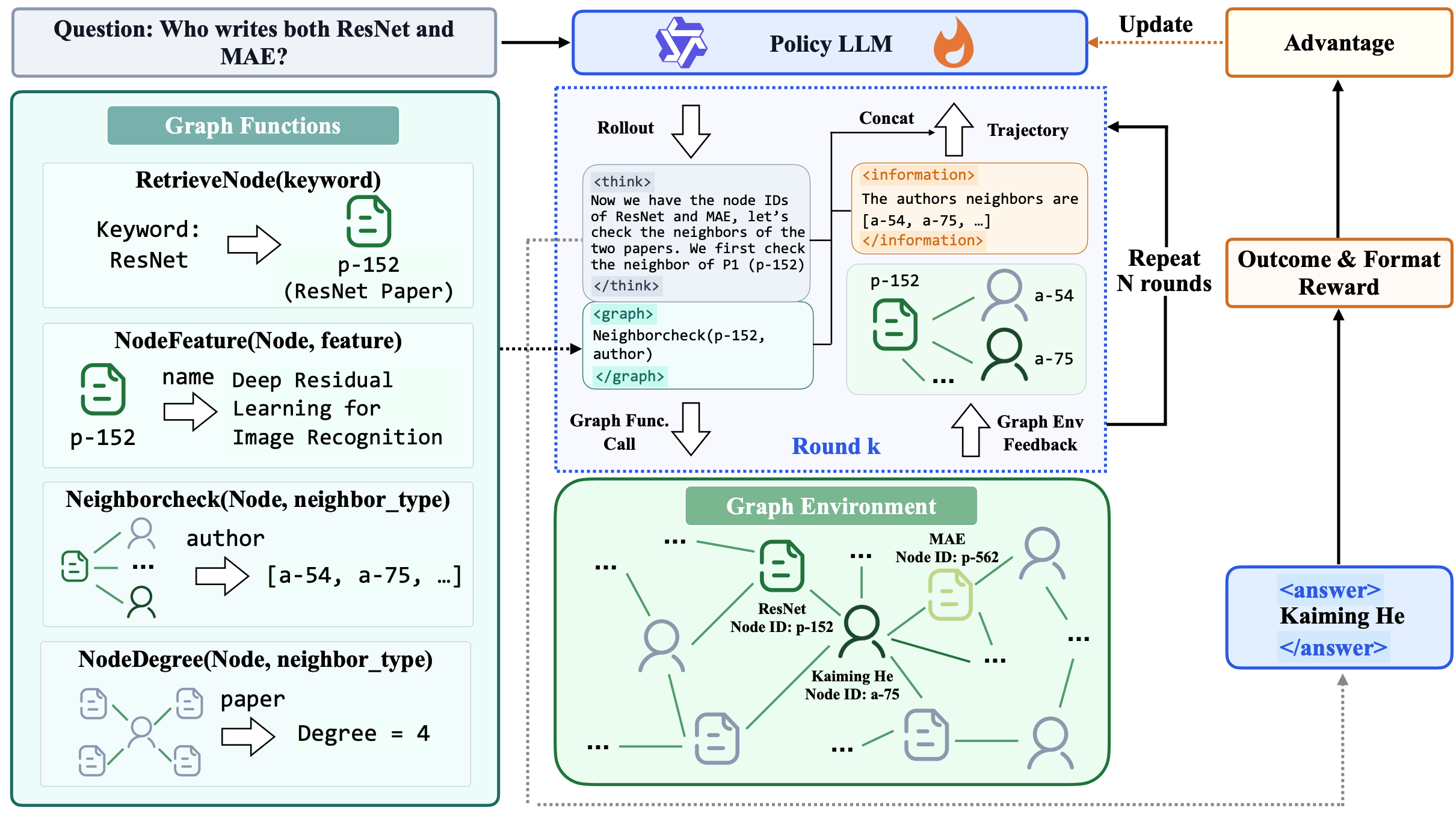
At round \(t\), the agent observes a state \(s_t\) comprising (1) the question \(x\), (2) the history of prior reasoning and actions, and (3) the graph observations returned by previous function calls.
The agent then selects an action \(a_t\) (i.e., a graph function call), receives an observation \(o_t\) (i.e., results returned by the function call), and updates its state.
An episode terminates when the agent produces a final answer or reaches a maximum of \(T\) rounds.
LLM Reasoning with Graph Interaction
We use a simple interaction format to expose tool use to the LLM. Specifically, the model generates a sequence interleaving three block types:
- Reasoning block:
<think> ... </think> containing non-executable reasoning text.
- Action block:
<graph> ... </graph> containing one or more function calls.
- Observation block:
<information> ... </information> appended by the environment after executing the action block.
The final output is produced in an <answer> ... </answer> block.
Graph Function Calls
To enable precise access over heterogeneous graphs, the agent invokes a small set of deterministic functions:
RetrieveNode(Text): returns a ranked list of node IDs relevant to a textual query (semantic entry point).
NodeFeature(NodeID, FeatureName): returns the requested textual field for a node.
NeighborCheck(NodeID, NeighborType): returns neighbor node IDs under a specified typed relation.
NodeDegree(NodeID, NeighborType): returns the count of neighbors under a specified typed relation.
Structural Difficulty of Graph Interaction
Graph interaction naturally decomposes into a sequence of information-seeking rounds. Based on the number of nodes surfaced in each round, we categorize rounds into two types:
- Singleton lookup round (S-round): Introduces exactly one node (e.g., resolving an entity mention to a unique node via
RetrieveNode).
- Neighborhood expansion round (E-round): Brings in multiple nodes (e.g., retrieving all co-authors of a researcher).
Based on this decomposition, we define three difficulty levels:
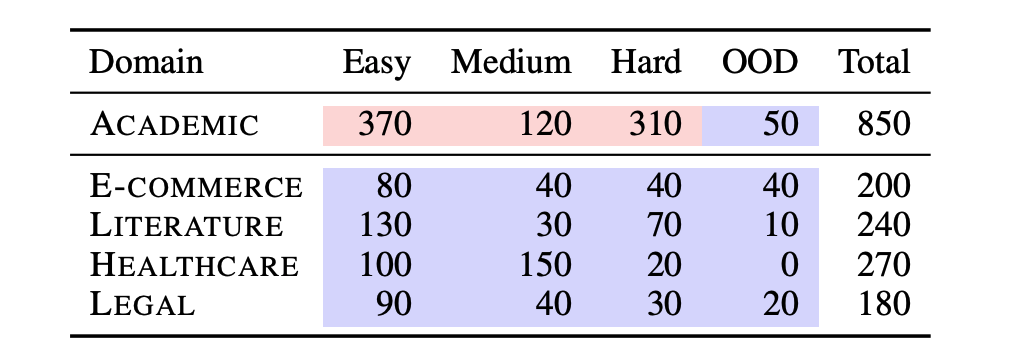
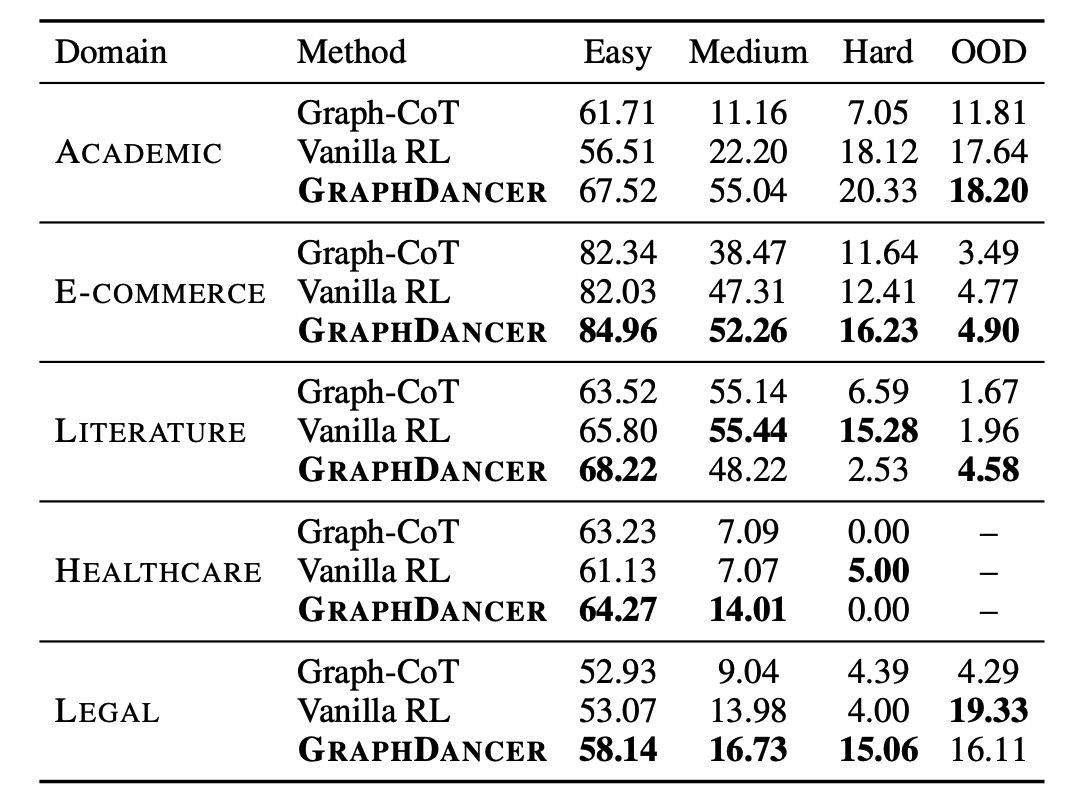
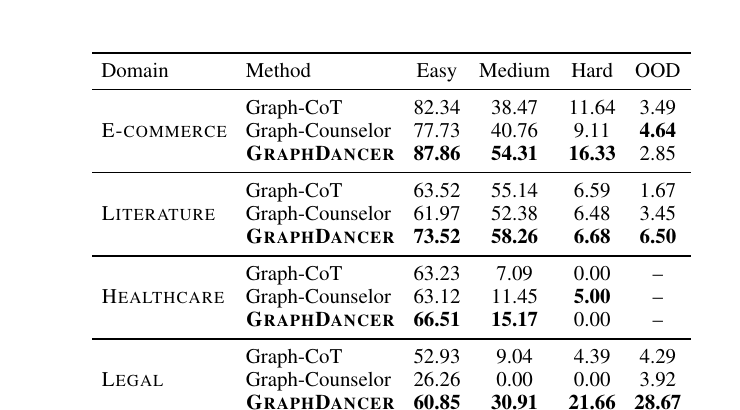
- Easy: Questions require a single round of information seeking.
- Medium: Questions require multiple rounds but at most one E-round.
- Hard: Questions require at least two E-rounds, reflecting repeated neighborhood expansions.
Two-Stage Post-Training
GraphDancer post-trains the policy in two stages. Stage 1 uses online reinforcement learning to teach the model how to interact with the graph. Stage 2 uses offline preference learning to make interactions more grounded and efficient. The same graph-aware curriculum organizes both stages.
Stage 1: Curriculum-PPO
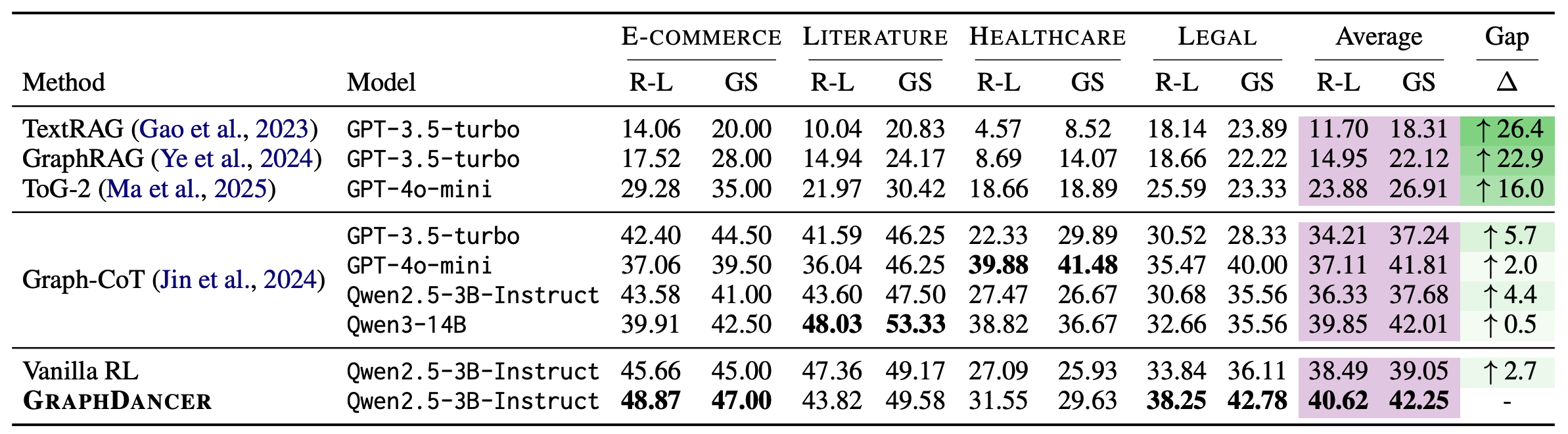
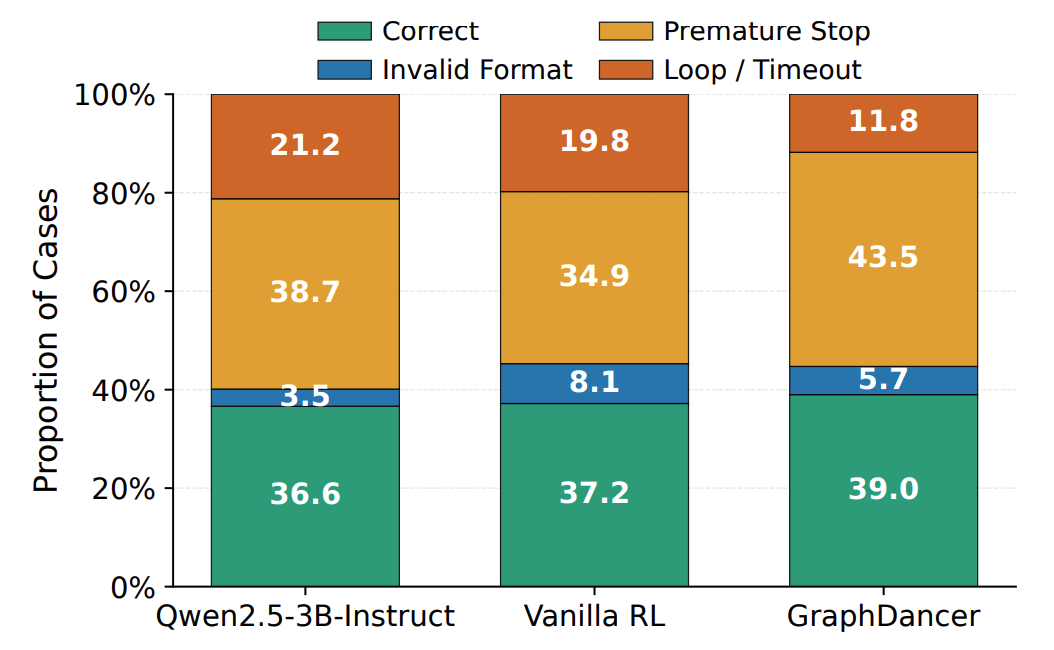
We optimize the policy with Proximal Policy Optimization (PPO) under a rule-based reward over executable graph calls. The reward combines three terms: (i) Exact Match against the gold answer as the primary correctness signal, (ii) a structural-validity penalty that fires when a correct answer is produced under an invalid trace, and (iii) a small Answer-Presence bonus on well-formed non-empty attempts to discourage degenerate outputs. No learned reward model is used.
At each training step, we sample a difficulty level from the graph-aware curriculum (see below) and uniformly select an instance within that level. This stage teaches navigation behavior: when to call which function, how to chain S- and E-rounds, and when to terminate.
Stage 2: Curriculum-DPO
Stage 1 produces a policy that interacts with the graph but still mis-calls tools and over-explores. Stage 2 refines the PPO checkpoint via Direct Preference Optimization (DPO) on self-generated preference pairs. For each training question, we sample M = 8 trajectories from the PPO policy and rank them by six trajectory-level keys with fixed tie-break priority:
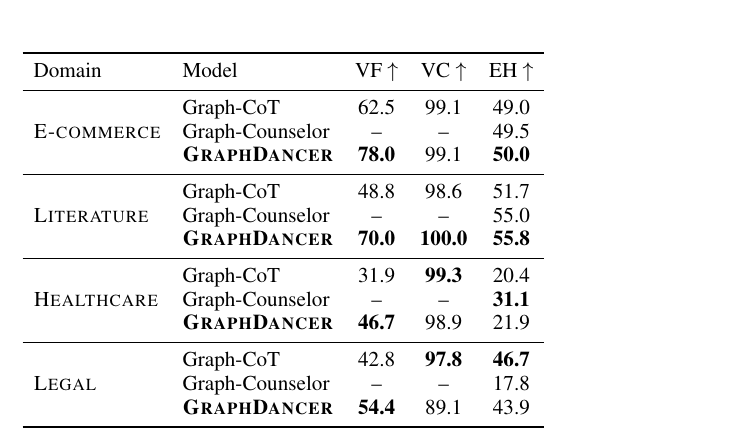
(EM, EH, VF, −Loop, −Invalid, −Rounds)
EM and EH (Evidence Hit) are correctness signals; VF (Valid Format) is schema adherence; the last three penalize loops, invalid tool calls, and unnecessary rounds. Rank-1 becomes the chosen response, rank-M the rejected one. DPO then nudges the policy toward chosen trajectories without a separate reward model.
Graph-Aware Curriculum
Both stages share a biased-mixture scheduler that combines a Gaussian curriculum schedule \(g(t,k)\) with a fixed level-bias prior \(q(k)\) over {Easy, Medium, Hard}, mixed by a time-varying weight \(\eta(t)\) (rising from 0.2 to 0.8 over training). Early on, the model sees mostly Easy questions (e.g., "Who are the authors of the ResNet paper?"). As training progresses, multi-hop and multi-round questions become more frequent (e.g., "Which venue did Kaiming He and Ross Girshick collaborate most?"), while controlled exposure to easier levels is preserved throughout.